http://www.reliableplant.com/Read/29106/continuous-improvement-partnering
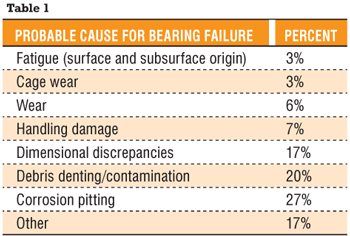
A major U.S. manufacturer of fabricated steel and metal products was experiencing a troubling and ongoing series of bearing failures on a dual line used for coating operations. A critical bearing located on the outboard roll of the dual line’s cleaning section would fail, necessitating repeated replacement. This occurred six times over the short period of four months, resulting in unscheduled downtime (to replace a failed bearing time after time) and lost productivity.
The bearing was the subject of frequent monitoring, with vibration analysis showing no readily detectable problems (all spectra appeared good). Nevertheless, it was only a matter of weeks before the latest replacement bearing took its turn for the worse and for reasons unknown.
Determining the root cause of the problem and arriving at a solution ultimately resulted from a unique three-way relationship between the steel manufacturer, on-site reliability engineers and locally based industry specialists (a team of highly trained engineers specializing in specific industries). Both the reliability engineers and locally based industry specialists, working hand in hand, had already become invaluable on-site resources for the operation, serving as intrinsic members of the manufacturer’s maintenance staff – regularly attending maintenance planning and scheduling meetings, convening with the customer’s reliability manager, and contributing input and suggestions along the way regarding optimized machinery health throughout the plant.
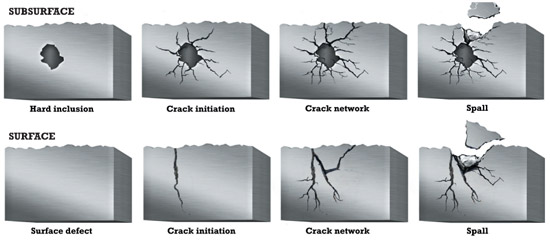
In this case, reliability engineers tagged the “bad actor” (failed bearing), and the industry specialists performed in-depth detective work into the root cause of failure. The conclusion was that the bearing was failing due to the roll’s thrusting in an axial direction, which the particular type of bearing could not accommodate. After documenting that the installed bearing could be suitably replaced by a more appropriate toroidal roller bearing that was specially designed to handle axial displacement without inducing additional axial forces of friction, a switch was made. In addition, a more suitable lubrication recommendation was adopted. The line has been running smoothly ever since without a bearing failure or process interruption. Value added over mean time between repairs (MTBR) to this steel producer was more than $230,000 in the first year, with cash flow breaking even in one month.
While this represents an example of how various bearing technologies can solve particular operational challenges, the compelling story runs much deeper and is illustrative of a trend that is gradually shifting the reliability landscape into a new territory – light years ahead of the conventional (and reactive) practice of engaging maintenance expertise only after the fact.
This case especially demonstrates how an operation can elevate reliability partnerships to an entirely new level by teaming with reliability and engineering professionals who become integral members of an organization’s maintenance framework. The on-the-scene professionals serve as focused sets of “eyes and ears” – supported by an array of relevant resources and expertise – to identify and diagnose machinery health problems, propose incisive recommendations to solve them, document all findings in writing, tally anticipated savings and efficiencies to substantiate the efforts, and make necessary fixes just in time.
This innovative approach (and advanced alternative) to traditional predictive maintenance practices effectively re-casts “supporting” players into the role of highly involved team players dedicated to the success of an operation’s initiatives for continuous improvement.
Creating Value
Advantages of this approach can extend well beyond the basic capability to make immediate, timely and long-term fixes to machinery assets.
First and foremost, while partnerships between operations and expert resources have always been recognized as critical to the success of reliability programs, the inclusion and participation of experts as actively involved members of an existing maintenance team can help to dramatically improve communications, advance relationships and knowledge, and result in newfound improvements in the health of assets across the board. Committed and sustained partnerships among all players will contribute significantly to the success of any reliability program and create value along the way.
Among value-created opportunities, this approach opens the door to readily available root-cause analysis – digging as deeply as necessary into machinery health problems to identify the true culprit(s) and take the appropriate remedial action(s). This practice goes well beyond those employed during typical predictive maintenance activities and can help prevent problems from recurring and taking productivity down with them.
Such improvement initiative programs can further benefit operations by introducing a training element for maintenance staff to equip them with insights into relevant procedures and technologies to help lower the total cost of operations and to recognize – and remedy – a problem when they detect one. Routine maintenance procedures can be improved, too, as maintenance education and awareness expand and new technologies are put into play.
For example, a U.S. taconite mining operation has partnered with a dedicated team of reliability engineers and locally based industry specialists with powerful results. The engineers conduct weekly predictive maintenance “routes” throughout the operation, provide reports advising machine conditions and recommended actions, and recover or preserve failed components (such as bearings) accompanied with a detailed history of the failure(s).
In turn the industry specialists, who are well versed in the mining field, perform damage analysis, report and document the root cause, and recommend improvements designed to eliminate repetitive failures. The specialists additionally provide on-site training associated with bearing and seal installations, as well as support during installations – all of which are highly valued by the mine.
Specific project successes at this site included the following:
• Root-cause failure analysis showed that conveyor pulley bearing failures were being caused by the ingress of contaminants and were resolved with an improved sealing system.
• Mill pinion bearing failures were linked after analysis to poor support for the bearing and ingress of contaminants, and were remedied with a recommended improvement to the bearing housing fit, custom sealing system solution, and pinion rebuild and replacement overseen by the industry specialists.
• Dust-collector fans suffered from poor installation practices, and training was subsequently provided to demonstrate the proper use of a hydraulic assist for installation (consisting of a hydraulic nut, hydraulic pump and dial indicator).
Making the Grade
While this real-world demonstration of teamwork can help reap measurable rewards from improved asset reliability, increased machinery uptime and enhanced productivity, such initiatives will be highly dependent on the level of expertise and the extent of a reliability partner’s experience, capabilities, and supporting resources and technologies.
Among the questions to ask when beginning the selection process for a reliability team to help realize optimized results consistent with a viable continuous improvement initiative include:
• Can knowledge and experience specific to your industry be demonstrated?
• Are the provider’s supporting resources (from technologies and services to analysis and training) sufficiently extensive?
• Does the provider understand how reliability influences the life-cycle management of assets?
• Can the team respond quickly when machinery problems unexpectedly occur?
• Can the team seamlessly blend with the existing maintenance function?
• Will written documentation on problems and recommended solutions be part of the package?
• Will the provider be suitably equipped to support equipment fixes?
• Can the provider demonstrate a close relationship with distributor sources to supply solutions in a timely manner when required?
• Will program progress be measured in a meaningful way? How?
• Will total cost of operations be demonstrably reduced over time?
The answers to these (and related) questions can help guide decision-making when selecting a reliability partner best equipped to sustain a continuous improvement initiative and accrue both immediate and long-term benefits for any operation.
About the Authors
Andy Rein is the director of SKF Reliability Systems and is based in Schaumburg, Ill. He can be reached via e-mail at Andrew.Rein@skf.com. James A. Oliver is the director of sales support engineering for SKF USA Inc., with headquarters in Lansdale, Pa. Contact James atjames.a.oliver@skf.com.

 As an instructor for the U.S. Postal Service, I often taught classes where 40 executives would spend two weeks at our executive center learning about all functions of the company and gaining a familiarity with the business of business. More than once, an executive would ask me what the cost of this experience was to the company. Now, the direct costs were easily calculated, so I would follow up with "What costs besides travel costs?"
As an instructor for the U.S. Postal Service, I often taught classes where 40 executives would spend two weeks at our executive center learning about all functions of the company and gaining a familiarity with the business of business. More than once, an executive would ask me what the cost of this experience was to the company. Now, the direct costs were easily calculated, so I would follow up with "What costs besides travel costs?"




 Of course, greases are formulated with oil, thickener and additives. While you may be familiar with the formulation of grease, do you know what grease consistency means and how it should influence your grease selection?
Of course, greases are formulated with oil, thickener and additives. While you may be familiar with the formulation of grease, do you know what grease consistency means and how it should influence your grease selection?


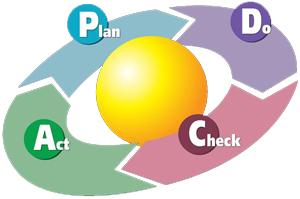 In the ever-changing world of continuous improvement, we must always remember to walk our own walk. If we, as continuous improvement leaders, are teaching and coaching people in the plan-do-check-act (PDCA) process, we too must ensure that we are leading by example. We must not vary our process from this cycle of improvement that works so very well.
In the ever-changing world of continuous improvement, we must always remember to walk our own walk. If we, as continuous improvement leaders, are teaching and coaching people in the plan-do-check-act (PDCA) process, we too must ensure that we are leading by example. We must not vary our process from this cycle of improvement that works so very well.